注:本文是根据小甲鱼的《零基础入门学习Python》一书关于爬虫实现有道翻译章节所做的的一个修改,有道翻译官方对有些参数做了“手脚“所以实现起来不那么容易了,所以我选择百度翻译作为新手的一个入门学习
1.首先需要导入urllib包的request模块
import urllib.request
2.小试牛刀
import urllib.request as g
response=g.urlopen("http://www.qq.com/")
html=response.read()
html=html.decode("utf-8")
print(html)
简单的几行代码就可以将腾讯网首页内容获取出来了,是不是很简单
3.下面就开始正式的练手了
首先来到百度翻译的首页百度翻译 如下图所示,按f12打开开发者模式,点击翻译按钮,在Network中就可以将你的一些请求信息获取到
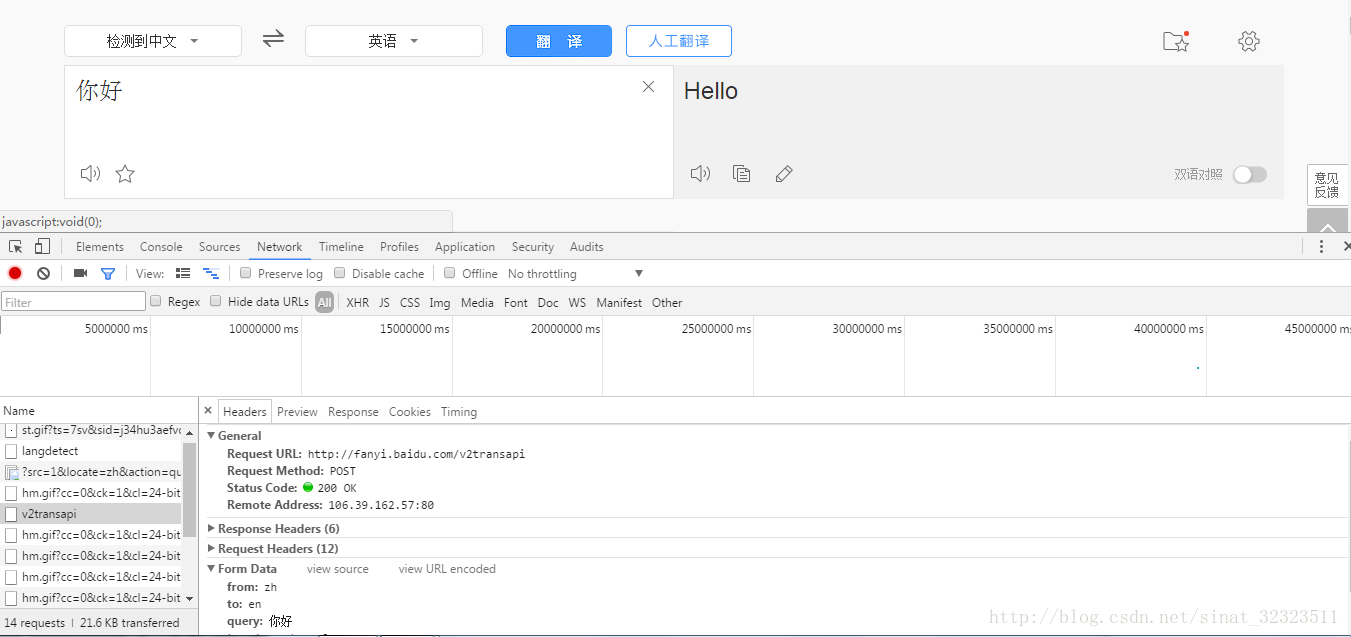
其中Request URL:http://fanyi.baidu.com/v2transapi以及下图的表单提交信息需要我们去获取的
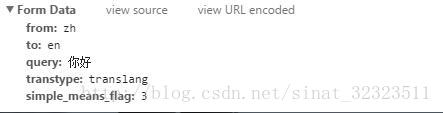
知道了这些,下面就很简单了
4.参考代码
import urllib.request
import urllib.parse
import json
content=0
while True:
content=input("请输入需要翻译的内容:")
if content!='quit':
url="http://fanyi.baidu.com/v2transapi"
data={}
data['from']='zh'
data['to']='en'
data['query']=content
data['transtype']='translang'
data['simple_means_flag']='3'
data=urllib.parse.urlencode(data).encode("utf-8")
response=urllib.request.urlopen(url,data)
html=response.read().decode("utf-8")
target=json.loads(html)
tgt=target['trans_result']['data'][0]['dst']
print("翻译的结果是:%s"% tgt)
else:
break
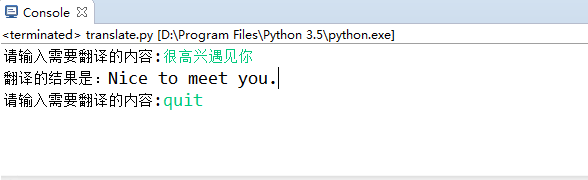
运行结果:
5.感悟
兴趣是最好的老师,希望大家在学习的时候多多的找到一些编程的乐趣,多动手去实现一些小的demo