本文为笔者根据Python静觅教程记录笔记,仅供学习使用
urllib库包含四个模块:
- urllib.request: 请求模块
- urllib.error: 异常处理模块
- urllib.parse: url解析模块
- urllib.robotparser(用的不多): robots.txt解析模块
本文主要介绍前三个用法
1.urllib.request的用法
import urllib.request
response=urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8'))
运行结果:

import urllib.parse
import urllib.request
data=bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
response=urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read().decode('utf-8'))
运行结果:

import urllib.request
response=urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read().decode('utf-8'))
运行结果:
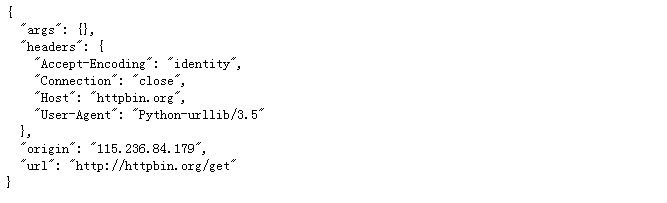
import socket
import urllib.request
import urllib.error
try:
response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print("TIMEOUT")
运行结果:
>>>TIMEOUT
2.状态码、响应头
import urllib.request
response=urllib.request.urlopen('http://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
运行结果:

import urllib.request
request=urllib.request.Request('http://www.python.org')
response=urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
运行结果同样可以获取Python网站上的内容
import urllib.request
url='http://httpbin.org/post'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36','Host':'httpbin.org'}
dict={'name':'Germey'}
data=bytes(urllib.parse.urlencode(dict),encoding='utf8')
req=urllib.request.Request(url=url,data=data,headers=headers,method='POST')
res=urllib.request.urlopen(req)
print(res.read().decode('utf-8'))
运行结果:

3.代理
import urllib.request
proxy_handler=urllib.request.ProxyHandler({'http':'http://61.152.81.193:9100'})
opener=urllib.request.build_opener(proxy_handler)
response=opener.open('http://httpbin.org/get')
print(response.read().decode('utf-8'))
运行结果:

4.Cookie的使用
①读取cookie信息
import http.cookiejar,urllib.request
cookie=http.cookiejar.CookieJar()
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
运行结果:

②.LWPCookieJar
import http.cookiejar,urllib.request
filename='cookie.txt'
cookie=http.cookiejar.LWPCookieJar(filename)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
运行完会将cookie信息保存在cookie.txt文件中

③MozillaCookieJar
import http.cookiejar,urllib.request
filename='cookie1.txt'
cookie=http.cookiejar.MozillaCookieJar(filename)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)

④读取cookie.txt信息请求网页
import http.cookiejar,urllib.request
cookie=http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
5.urllib.error异常处理
from urllib import request,error
try:
response=request.urlopen('http://www.51ashin.cn/index.html')
print('你好')
except error.URLError as e:
print(e.reason)
结果:>>>Not Found
from urllib import request,error
try:
response=request.urlopen('http://www.51ashin.cn/index.html')
print('你好')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Successful!')
优先打印出URLError子类HTTPError的错误信息
Not Found
404
Date: Sat, 22 Jul 2017 08:54:46 GMT
Server: Apache/2.2.15 (CentOS)
Content-Length: 288
Connection: close
Content-Type: text/html; charset=iso-8859-1
注意:如果将URLError写在前面就会先打印出NotFound
from urllib import request,error
import socket
try:
response=request.urlopen('http://www.51ashin.cn/index.html',timeout=0.001)
except error.URLError as e:
print(type(e.reason))
if isinstance(e.reason,socket.timeout):
print('TIMEOUT')
运行结果:
>>><class 'socket.timeout'>
>>>TIMEOUT
6.urllib.parse
######①urllib.parse.urlparse
urllib.parse.urlparse(urlstring,scheme='',allow_fragments=True)
from urllib.parse import urlparse
result=urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result),result,sep='\n')
运行结果:

没写协议类型时,指定协议类型
from urllib.parse import urlparse
result=urlparse('www.baidu.com/index.html;users?id=5#comment',scheme='https')
print(type(result),result,sep='\n')
运行结果:

当前面写了协议类型时,指定协议类型不生效
from urllib.parse import urlparse
result=urlparse('http://www.baidu.com/index.html;users?id=5#comment',scheme='https')
print(type(result),result,sep='\n')
运行结果:

allow_fragments=False
from urllib.parse import urlparse
result=urlparse('http://www.baidu.com/index.html;users?id=5#comment',allow_fragments=False)
print(type(result),result,sep='\n')
运行结果:

from urllib.parse import urlparse
result=urlparse('http://www.baidu.com/index.html#comment',allow_fragments=False)
print(type(result),result,sep='\n')
运行结果:
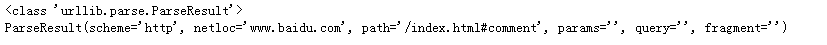
#####②urllib.parse.urlunparse
from urllib.parse import urlunparse
data=['http','www.baidu.com','index.html','user','id=5','comment']
print(urlunparse(data))
输出:>>>http://www.baidu.com/index.html;user?id=5#comment
#####③urllib.parse.urljoin
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com','FAQ.html'))
print(urljoin('http://www.baidu.com','http://www.sina.com.cn'))
print(urljoin('http://www.baidu.com','?category=2#comment'))
print(urljoin('www.baidu.com','?category=2#comment'))
print(urljoin('www.baidu.com#comment','?category=2'))
运行结果:

#####④urllib.parse.urlencode(将字典格式的数据转换为请求参数)
from urllib.parse import urlencode
params={'name':'sam','age':22}
base_url='http://www.baidu.com?'
url=base_url+urlencode(params)
print(url)
运行结果:http://www.baidu.com?name=sam&age=22