本文为笔者根据Python静觅教程记录笔记,仅供学习使用
1.实例引入
import requests
response=requests.get('http://www.baidu.com')
print(type(response))
print(response.status_code)
print(type(response.text))
print(response.text)
print(resposne.cookies)
运行结果:

2.各种请求方式
import requests
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
3.基本GET请求
- 基本写法
import requests
response=requests.get('http://httpbin.org/get')
print(response.text)
- 带参数get请求—-写法一
import requests
response=requests.get('http://httpbin.org/get?name=Ashin&age=20')
print(response.text)
运行结果:

- 带参数get请求—-写法二
import requests
data={'name':'Ashin','age':20}
response=requests.get('http://httpbin.org/get',params=data)
print(response.text)
- 解析json
import requests
import json
response=requests.get('http://httpbin.org/get')
print(type(response.json()))
print(response.json())
print(type(json.loads(response.text)))
print(json.loads(response.text))
运行结果:

- 获取二进制数据
import requests
response=requests.get('https://assets-cdn.github.com/favicon.ico')
with open('favorite.ico','wb') as f:
f.write(response.content)
运行后将图片保存至工作目录
- 添加headers
import requests
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
response=requests.get('https://www.zhihu.com/explore',headers=headers)
print(response.text)
不加headers参数:
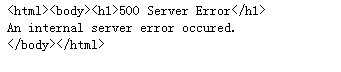
加上headers参数就能正确的将页面信息打印出来
4.基本POST请求
- 带参数
import requests
data={'name':'Ashin','age':20}
response=requests.post('http://httpbin.org/post',data=data)
print(response.text)
运行结果:

- 带参数,请求头信息
import requests
data={'name':'Ashin','age':20}
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
response=requests.post('http://httpbin.org/post',data=data,headers=headers)
print(response.text)
运行结果:

5.响应
- resposne属性
import requests
response=requests.get('http://www.jianshu.com/')
print(type(response.status_code),response.status_code)
print(type(response.headers),response.headers)
print(type(response.cookies),response.cookies)
print(type(response.url),response.url)
print(type(response.history),response.history)
运行结果:

- 状态码判断
import requests
response=requests.get('http://www.jianshu.com/')
exit() if not response.status_code==200 else print('Request Successfully')
>>>Request Successfully
import requests
response=requests.get('http://www.jianshu.com/')
exit() if not response.status_code==requests.codes.ok else print('Request Successfully')
>>>Request Successfully
6.高级操作
- 文件上传
import requests
files={'file':open('favorite.ico','rb')}
response=requests.post('http://httpbin.org/post',files=files)
print(response.text)
- 获取cookie
import requests
response=requests.get('http://www.baidu.com/')
print(response.cookies)
for key,value in response.cookies.items():
print(key+'='+value)
>>><RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
>>>BDORZ=27315
- 会话维持
①模拟登陆一
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
response=requests.get('http://httpbin.org/cookies')
print(response.text)
输出:
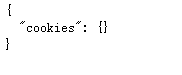
②模拟登陆二
import requests
s=requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response=s.get('http://httpbin.org/cookies')
print(response.text)
运行结果:
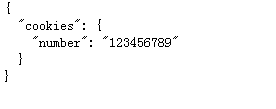
- 证书验证
import requests
response=requests.get('https://www.12306.cn')
print(response.status_code)
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response=requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
注意,不加verify=False,会报错,加上这句,正常返回
>>>200
加上证书
import requests
response=requests.get('https://www.12306.cn',cert=('/path/server.crt','/path/key'))
print(response.status_code)
7.代理设置
- 基本用法
import requests
proxies={'http':'http://61.152.81.193:9100'}
response=requests.get('http://httpbin.org/get',proxies=proxies)
print(response.text)
运行结果:

- 带用户名密码的代理
import requests
proxies={'http':'http://user:password@61.152.81.193:9100/'}
response=requests.get('http://httpbin.org/get',proxies=proxies)
print(response.status_code)
- socks代理
pip install 'requests[sockes]'
import requests
proxies={'http':'http://user:password@61.152.81.193:9100/'}
response=requests.get('http://httpbin.org/get',proxies=proxies)
print(response.status_code)
8.超时设置
import requests
from requests.exceptions import ConnectTimeout
try:
response=requests.get('http://httpbin.org/get',timeout=0.1)
print(response.status_code)
except ConnectTimeout:
print('Timeout')
>>>Timeout
9.认证设置
import requests
from requests.auth import HTTPBasicAuth
r=request.get('http://120.27.34.24:9001/',auth=HTTPBasicAuth('user','123'))
print(r.status_code)
>>>200
10.异常处理
import requests
from requests.exceptions import ConnectTimeout,HTTPError,RequestException
try:
response=requests.get('http://httpbin.org/get',timeout=0.1)
print(response.status_code)
except ConnectTimeout:
print('Timeout')
except HTTPError:
print('HTTP Error')
except RequestsException:
print('Error')
>>>Timeout