直接进入正题吧,之前只会用Python简单的字符串操作来爬取网络上的内容,这对结构不明显网页很难匹配,然后花了一下午时间看了一下BeautifulSoup中文手册,结合老师布置给我的一个任务,写了一个爬取精美图片库植物图片的小程序。效果不错,现在这里记录下来。
1.安装BeautifulSoup
$ pip install beautifulsoup4
2.源程序
# -*- coding:utf-8 -*-
import urllib.request
import datetime
import os
import random
import re
import urllib
import time
from bs4 import BeautifulSoup
from urllib.error import URLError
def url_open(url):
req=urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')
req.add_header('Referer','http://www.85814.com/zhiwu/')
response=urllib.request.urlopen(req)
html=response.read()
return html
def get_soup(url):
html=url_open(url)
soup=BeautifulSoup(html,'html.parser')
return soup
def get_cat_url(url):#获取每类的地址
soup=get_soup(url)
site='http://www.85814.com'
for each in soup.find(id='q').i.find_all('a'):
dirname=each.string
try:
os.makedirs('F:\\images\\'+dirname)
except FileExistsError as e:
pass
os.chdir('F:\\images\\'+dirname)
cat_url=site+each['href']#每一类首页的地址
all_urls=get_all_page_url(cat_url)#每一类每一页的地址
for content_url in all_urls:
get_imgs(content_url)
os.chdir(os.pardir)
def get_all_page_url(url):
soup=get_soup(url)
page_urls=[]
page_urls.append(url)
btn=soup.find('a',string=re.compile('尾页'))
if btn is not None:
page_num=btn['href'].split(sep='_')[1]#得到,例如:玫瑰花返回12
for i in range(1,int(page_num)+1):
page_urls.append(url+'_'+str(i))
return page_urls
def get_imgs(url):#保存每一页的简介图片
soup=get_soup(url)
for content in soup.find(id='l').find_all('a'):
#filename=content.img['alt']
img=content.img['src']
img=urllib.parse.quote(img,safe='/:?=&')
img=url_open(img)
with open('IMG_'+str(datetime.datetime.now().strftime("%Y%m%d%H%M%S"))+'.jpg','wb') as f:
f.write(img)
time.sleep(1)
def download():
print("下载中...")
site='http://www.85814.com/zhiwu/'
get_cat_url(site)
print("下载完成^-^")
if __name__=='__main__':
download()
这里附上链接:程序链接
3.运行结果图
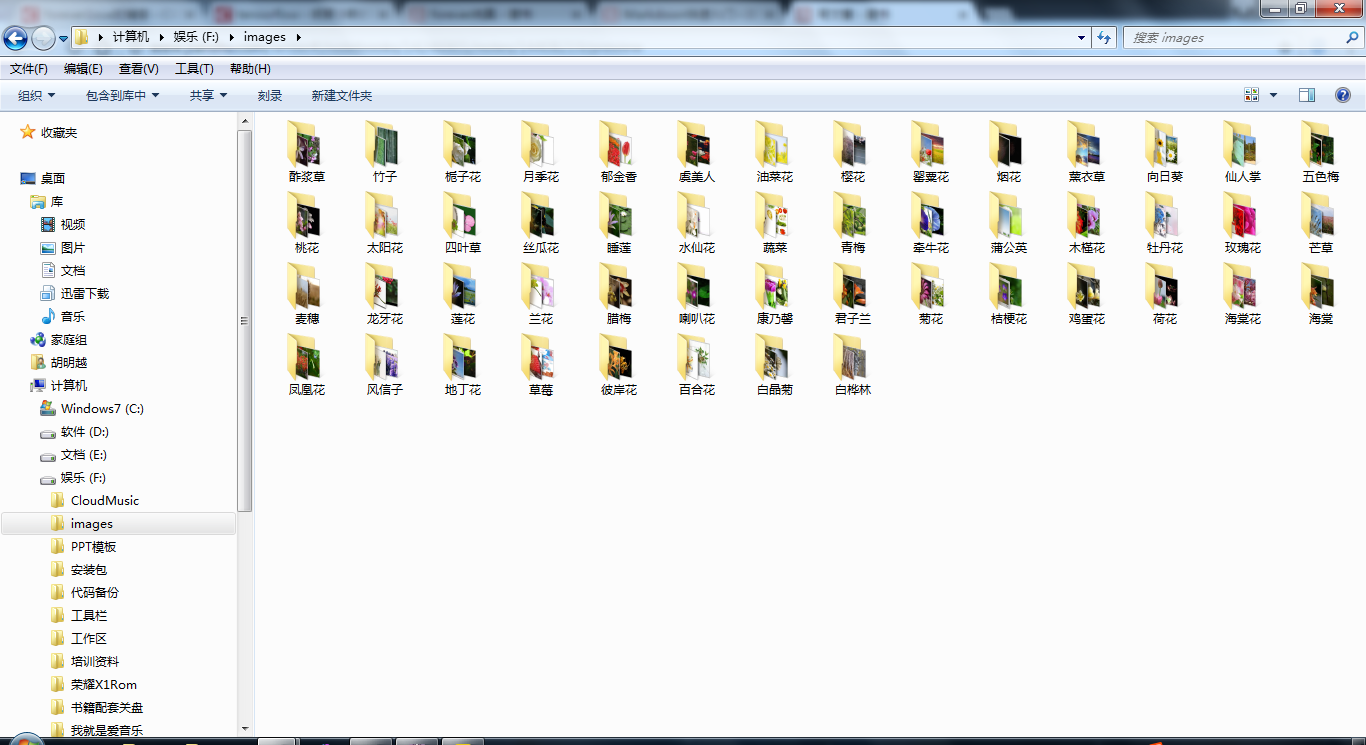
还不错~。~