前言:图像识别是深度学习的一个热门的研究方向,今天要介绍给大家的就是利用深度学习解决图像识别问题的第一大步,即数据的收集。话不多说,下面就是满满的干货。
一、抓包分析
本文图像数据收集是基于百度图片实现的。首先,我们使用浏览器(浏览器不限,本文中使用的是Chrome浏览器)打开百度图片的首页,按F12打开开发调试工具,输入关键字“苹果”,然后回车,观察一下网页抓取到的包。这一步主要是为了找出百度图片是如何加载图片的。通过分析发现,百度使用的是ajax异步加载的方式,链接如下图所示:
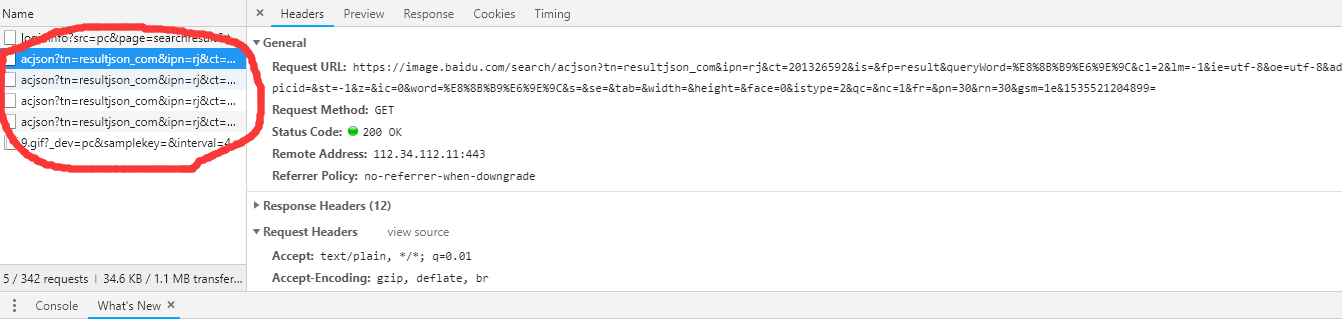
进一步地,我们发现表单需要填写多个字段。
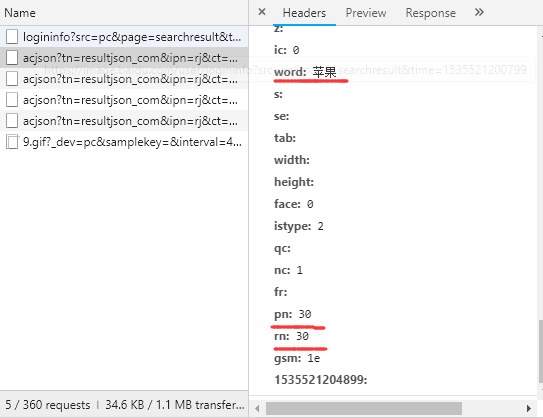
重要的几个字段为:
- word:表示要搜索的关键字
- pn:表示总共显示的图片数,为30*页数
- rn:表示每次显示的图片数,默认为30,最好不要更改。因为百度图片采用的是瀑布流的方式加载图片的,所以需要这个参数。
由于百度图片目前还没有使用什么反爬虫机制,了解了这些,接下来就简单了,下面直接上源程序。
二、源程序
1.config.py
"""
环境配置:python3.5
pip install requests
"""
#默认参数,不用改
GROUP_START=1
#配置你想要下载每种树的张数,每种GROUP_END*30张
GROUP_END=1
#配置你想要下载的树种
IMAGE_LIST=['葡萄','香蕉']
#保存路径
DIR_PATH='F:\\爬虫\\test'
2.main.py
from hashlib import md5
import json
from json.decoder import JSONDecodeError
from multiprocessing import Pool
import os
from urllib.parse import urlencode
import requests
from requests.exceptions import RequestException
from config import *
def get_page_index(offset,keyword):
headers={
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer':
'https://image.baidu.com/'
}
data={
'tn':'resultjson_com',
'ipn':'rj',
'ct':'201326592',
'fp':'result',
'lm':-1,
'ie':'utf-8',
'oe':'utf-8',
'st':-1,
'word':keyword,
'face':0,
'istype':2,
'nc':1,
'step_word':keyword,
'pn':offset*30,
'rn':30,
'gsm':'3c',
}
url='https://image.baidu.com/search/acjson?is=&queryWord+=&adpicid=&z=&s=&se=&tab=&width=&height=&qc=&fr=&1512794125636='+urlencode(data)
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
return None
except RequestException:
print("请求索引页出错!")
return None
def parse_page_index(keyword,html):
try:
data=json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
if item and item is not None:
download_image(keyword,item.get('thumbURL'))
except JSONDecodeError:
pass
def download_image(keyword,url):
try:
response=requests.get(url)
if response.status_code==200:
print(url)
save_image(keyword,response.content)
except RequestException as e:
# print("请求图片出错!"+e)
pass
def save_image(keyword,content):
path=os.path.join(DIR_PATH,keyword)
if not os.path.exists(path):
os.makedirs(path)
os.chdir(path)
file_path='{0}.{1}'.format(md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
os.chdir(os.pardir)
def main():
for keyword in TREE_LIST:
for offset in range(GROUP_START,GROUP_END+1):
html=get_page_index(offset,keyword)
parse_page_index(keyword,html)
if __name__=="__main__":
print("开始下载...")
main()
print("下载完成...")
三、运行结果
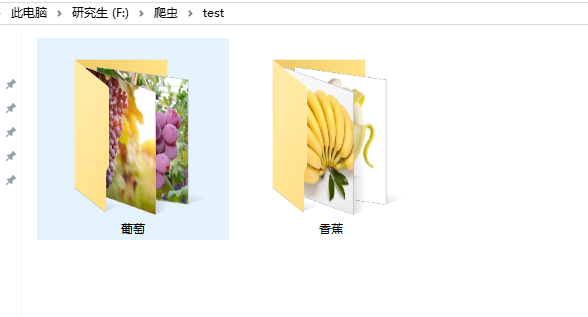
Note:本文撰写于2018-09-22,截止目前为止,该程序还是能正确运行,但是不保证以后百度图片不采取一定的反爬虫机制。并且基于此方法收集到的图像不可避免会有一些“脏”数据,所以这就需要我们手动去筛选了。