前言:深度神经网络中,我们听到的最多的词就是梯度消失(gradient vanishing )和梯度爆炸(gradient exploding),那么这两个词到底表示什么意思呢?今天就让我们来一探究竟。
一.梯度消失与梯度爆炸问题简述
层数比较多的神经网络模型在使用梯度下降法对误差进行反向传播时会出现梯度消失和梯度爆炸问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。 例如,对于图1所示的含有3个隐藏层的神经网络,梯度消失问题发生时,靠近输出层的hidden layer 3的权值更新相对正常,但是靠近输入层的hidden layer1的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,扔接近于初始化的权值。这就导致hidden layer 1 相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。梯度爆炸的情况是:当初始的权值过大,靠近输入层的hidden layer 1的权值变化比靠近输出层的hidden layer 3的权值变化更快,就会引起梯度爆炸的问题。
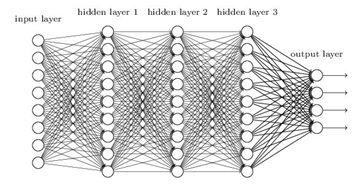
二.利用数学公式推导梯度消失与梯度爆炸的原因
下面以一个简单的含有三个隐藏层的单神经元神经网络为例,激活函数使用sigmoid,如图2所示。

易知:
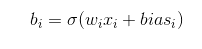
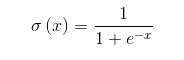
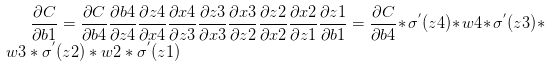
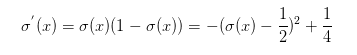
可见sigmoid的导数的最大值为1/4,通常初始化的网络权值w通常都小于1,从而有
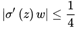
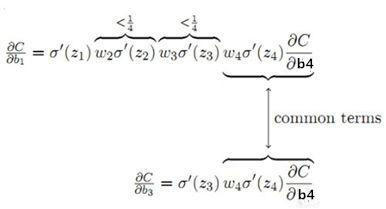
如下图所示:前面的层比后面的层梯度变化更小,故变化更慢,从而引起了梯度消失问题。
当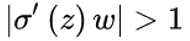
,也就是w比较大的情况。则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。 通常来说当激活函数是sigmoid时,梯度消失比梯度爆炸更容易发生。
三.如何解决梯度消失与梯度爆炸?
- 用ReLU、Leaky ReLU、PReLU、RReLU、Maxout等替代sigmoid函数。
- 用Batch Normalization。
- LSTM的结构设计也可以改善RNN中的梯度消失问题。
Reference
https://blog.csdn.net/cppjava_/article/details/68941436